
CD Without CI
December 12, 2019
Conventional wisdom tells us that an automated test pipeline is the necessary first piece to Continuous Deployment. I challenge that thinking.Editorial note: Since writing this in 2019, I’ve come to realize that the terminology I use here is sloppy. I fell into the common trap of conflating the practice of Continuous Integration (CI) with having a CI Pipeline in place. Further, the idea that one can practice Continuous Delivery without practicing Continuous Integration is also wrong. But if we look past the conflated terminology, I believe the substance of this post still stands, and offers a valuable approach to help many people make the transition to true Continuous Delivery.
Conventional wisdom tells us that an automated CI (Continuous Integration) pipeline is the necessary first piece to a CI/CD (Continuous Integration/Continuous Deployment) pipeline. Typical advice for adding CI/CD to an existing project goes something like this:
- Write a bunch of automated tests, broadly employing the test pyramid. Aim for 100% test coverage.
- Automate the running of your unit tests for every code change with a CI tool.
- Find some way to instill responsibility and trust into every member of the team.
- Finally automate the deployment process.
In this post, I want to challenge the conventional wisdom, and offer a way to skip steps 1-3, and to do so responsibly, and with even less FUD than the conventional wisdom can offer.
Definitions
Before we get too far into the weeds, let me offer some definitions. CI/CD has some broadly-accepted definitions, but let me put a fine point on what precisely I’m talking about, just to avoid any confusion.
-
Continuous Integration
Wikipedia offers a good general definition, but I generally operate on a more specific definition:
Continuous Integration (CI) is the practice of merging all developers’ changes into a shared mainline every time they complete a change.
My definition assumes a trunk-based development approach, but it can also work with many other common workflows.
-
Continuous Deployment and Continuous Delivery
These two concepts are often conflated, if only because they often share an acronym (I like to use CDE for Continuous Delivery, to distinguish, and will use this convention from now on). And they are related, but the distinction is often important. Here are my definitions:
Continuous Deployment (CD) is the practice of automatically deploying software into production any time the mainline branch changes.
In contrast,
Continuous Delivery (CDE) is the practice of packaging software into a deployable state any time the mainline branch changes.
An important thing to notice here is that both CD and CDE, by my definition, are triggered by the same event: the mainline branch changing. This means that there cannot be a manual step, even if it’s only to press a button, between delivery (packaging) and deployment. If you have an automated deployment script that runs when you hit “Deploy”, that’s better than a manual deployment process, but it is not CD!
For most projects, Continuous Deployment should be the goal. This article is about achieving Continuous Delivery, but since Continuous Delivery is a strict subset of Continuous Deployment, it applies equally well to the latter.
Fear, uncertainty and doubt

There are many reasons people cite for not employing CDE (yet). The most common reason I’ve heard is a lack of (sufficient) automated tests to instill the confidence necessary to automatically deliver software.
This is underlined by the wikipedia article on the subject, which cites (among others), two salient obstalces to CDE adoption:
- Lack of test automation: Lack of test automation leads to a lack of developer confidence and can prevent using continuous delivery.
- Tests needing a human oracle: Not all quality attributes can be verified with automation. These attributes require humans in the loop, slowing down the delivery pipeline.
Other reasons are usually variations on this theme. Let me enumerate a few I’ve run into over the years:
- User Acceptance Testing must happen before delivery
- Sprint demos must happen before delivery
- The CTO needs to approve all changes before delivery
You’re probably noticing the theme here. Every common objection to CDE boils down to essentially one thing: A human must validate the changes before they are delivered.
And this, per se, isn’t a problem. What I do see as a problem is the common knee-jerk reaction to this situation:
Then we cannot continuously deliver until our automation is sufficiently advanced to eliminate the need for human validation.
The fear of imperfect automation, and in some cases the dogmatic belief that humans cannot be automated away, is the obstacle to CDE adoption.
Overcoming the fear

So how do you overcome this fear?
Actually… you don’t!
The fear, broadly speaking, is appropriate. Humans should be involved in software validation. That dogmatic belief is actually correct. The problem isn’t actually the fear. The problem lies elsewhere.
Before I spill the beans on where I think the problem is, though, let’s take a look at the evolution of a typical CI/CD pipeline.
A typical deployment pipeline
This is based loosely on my experience working with the eCommerce development team at Bugaboo, but it should be reminiscent of many projects.
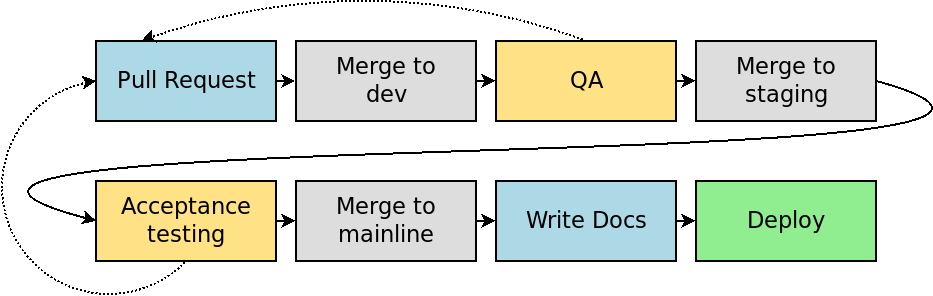
This pipeline involves several manual phases: Writing the pull request, Quality Assurance testing (QA), Acceptance Testing, and writing documentation or release notes. Several of these stages have the potential to restart the entire pipeline, by sending work or tweaks back to the developer to fix a bug or tweak a feature.
The goal is usually to achieve a pipeline that looks a bit more like this:
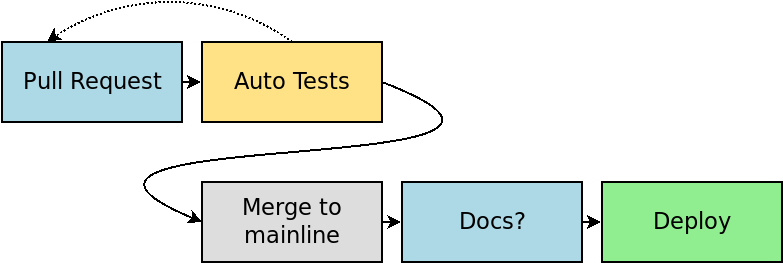
By automating QA with better unit and integration tests, and possibly even automating Acceptance Testing with techniques like Behavior-driven development, the goal is to remove the human validation from the equation.
Often documentation and release notes are overlooked here, thus the question mark in my diagram. The most prevalent attitude I’ve seen here is “docs aren’t code, so they don’t matter to our pipeline”, and then documentation is manually updated sometime after deployment.
A different approach
Many teams have achieved CI/CD success with this approach. But it’s usually a very long process, taking months or even years, to automate enough that the team feels confident with CD or CDE.
The approach I prefer instead, is to simply re-organize the legacy pipeline, without automating any of the validation steps. Yes, you read that right: my goal is not to automate any of the validation.
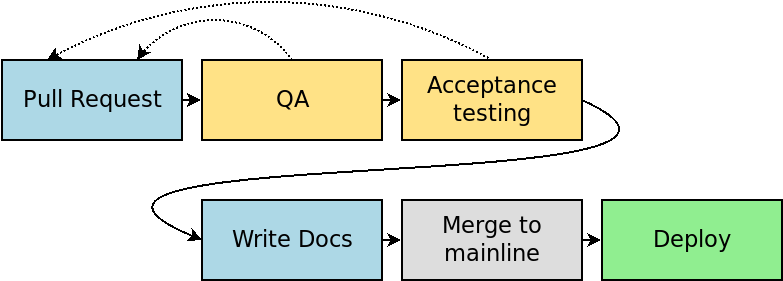
A quick side rant: Note that merging to dev and staging have been eliminated. This assumes trunk-based development, which is far superior to the over-complicated GitFlow in every situation I’ve ever seen. GitFlow should be banished, because it assumes, and therefore encourages, manual work between every branch.
What’s important to see about this new diagram is that every manual step still exists. Writing code, manual QA, manual acceptance testing, and manual documentation are all still there. The only difference is the order in which they happen.
“Yeah, but how can we do QA and Acceptance Testing before deploying?” you may say. Okay, you got me. You have a valid point. I left out one piece of magic from my diagram. Let me remedy the situation:
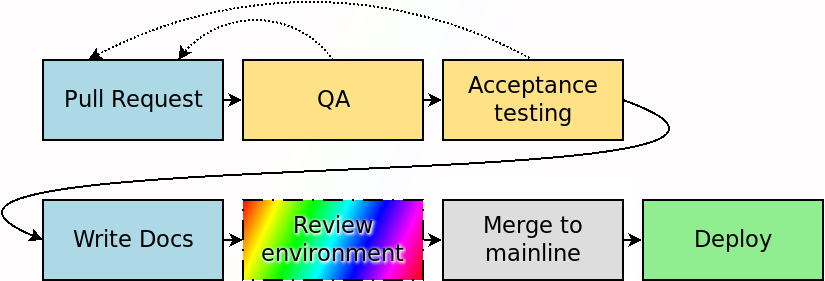
With the (conceptually) simple addition of a review environment before the merge to mainline, all of the human validation steps can take place before that final merge. QA testing, acceptance testing, and writing release notes and documentation can all happen while the code is still comfortably sitting in a feature branch. The only reason these are normally done later is habit–habit formed by working on waterfall projects.
This is the key take-away from the article: It’s just a matter of “front-loading” all the manual work to earlier in the process.
Of course simple concepts aren’t always simple in practice. I can already hear your brain screaming at me about all of the reasons this won’t work in your situation.
For the rest of this article, let me do my best to set your brain at ease on all of these objections by describing a few different ways you can perform the magical “review” step.
“Review” is just glorified “Staging”
You probably already have a staging environment. I’d even venture a guess that most readers do QA and acceptance testing in this staging environment, and not in production. If this describes you, then simply substitute “staging environment” for the magic step on my pipeline chart.
Often the simplest and quickest way to switch to this new CD-without-CI approach is to re-purpose your existing staging environment. This usually requires only minor changes to your existing CI configuration. Many teams use a specific branch that is always deployed to staging. This is a great approach. The key is to push to this branch before pushing to your mainline branch (dev in GitFlow).
A conventional staging environment, such as you might find with GitFlow, looks something like this.

Work flows from a feature branch, to staging, then after validation, finally to master.
The approach I advocate looks only slightly different on paper, but the implications are significant.

Work is still done in a feature branch, and it still flows to staging for validation, but the staging (or review) environment is considered ephemeral. There’s nothing “special” about it, as far as the workflow is concerned. It’s only a sandbox. Every push to staging is eventually thrown away.
Finally, once all validation is complete, the pull request for the feature can be merged into master, and CD(E) is kicked off.
This subtle change might seem trivial at first blush, but it offers a number of advantages:
- It demotes the staging environment from having a special place in your deployment pipeline, possibly with gatekeeper scripts and/or procedures before and after it, to being just a tool to get a job (validation) done. It no longer holds any “official” role in the pipeline.
- It eliminates the burden of resolving merge conflicts. It’s not special, so it doesn’t matter if Bob’s in-progress feature merges cleanly with Alice’s at this stage. Just force push to staging any time you want to (well, as long as nobody else is actively using that branch).
- And as a bonus, it makes your git history a lot easier to read.
I hope from this it’s clear that for any project where a staging environment is feasible, review environments should also be feasible, just by changing some assumptions about staging.
More, more, more
Of course, on a large project, there can be a lot of contention over a single review environment. If Bob is using the review environment for his feature, Alice must wait until he’s done. That may be 15 minutes, or 6 days, depending on the complexity of the feature, and how much testing is needed.
 One way to resolve this problem is to create additional review environments. This may be simple or complex, depending on the complexity of the project. In many cases, all review environments can share the same external dependencies (such as databases, or third-party APIs), which can simplify the configuration. But if testing database migration scripts is part of your process, you may need to create new database instances for each review environment. I leave these details in the capable hands of your infrastructure team. You just need to be sure to consider these things.
One way to resolve this problem is to create additional review environments. This may be simple or complex, depending on the complexity of the project. In many cases, all review environments can share the same external dependencies (such as databases, or third-party APIs), which can simplify the configuration. But if testing database migration scripts is part of your process, you may need to create new database instances for each review environment. I leave these details in the capable hands of your infrastructure team. You just need to be sure to consider these things.
How many review environments should you build? Only you can answer this, and it depends a lot on how your teams work. There are different strategies you might choose:
- Numbered review environments. You may have environments 1-4, and sign in/out for each on a whiteboard or via chat, to make sure only one person is using an environment at a time.
- One environment per team. If you’re a multi-team project, one effective strategy could be to assign a review environment per team. You may still have some contention, but at least you’ll know the other person using it is just across the room from you, and you can more easily coordinate than with someone you don’t even know in a different building.
- One environment per developer. If you have plenty of money to throw at the problem, you could simply assign a review environment to each developer as they join the team. Each developer can then test his or her own features without any worry of taking too long for another team.
- One environment per feature branch. This is my favorite, and it deserves special attention…
Dynamic review environments
 The gold-standard for review environments is dynamic review environments that are automatically generated for each pull request. Your pipeline assigns a unique URL to each environment, perhaps named after the branch. This URL can be used by QA, or for acceptance testing, even for sprint demos.
The gold-standard for review environments is dynamic review environments that are automatically generated for each pull request. Your pipeline assigns a unique URL to each environment, perhaps named after the branch. This URL can be used by QA, or for acceptance testing, even for sprint demos.
The use of dynamic review environments provides several advantages over fixed environments:
- Absolutely no contention issues. This is even more flexible than one environment per developer, as a single developer can use multiple review environments when the need calls for it.
- Cost savings. By only running review environments when they’re needed, you stand to save money over having potentially idle environments consuming resources. With the addition of auto-scaling, this can be very powerful.
- Reproducible installations. By exercising the set-up (and tear-down) of an environment for every build, you know that you’ll be prepared if you ever need to install a new instance in production, whether it be for disaster recover, or just scaling or moving data centers.
- It’s just really cool! This is the kind of thing techies like to brag about at developer meetups. Wouldn’t you like some bragging rights?
Having said that, there can be prohibitive technical challenges for some projects, especially those with complex external dependencies.
The ideal candidate for dynamic review environments is a self-contained project that can be run in a Docker container. My preference is to deploy to a Kubernetes cluster, which can usually be configured for easy auto-scaling. AWS Elastic Beanstalk can also provide this functionality, if you prefer that route, as well can many other cloud platform solutions.
If your project is simple enough, GitLab’s Auto DevOps can be an attractive solution as well. It integrates with an existing Kubernetes cluster, or you can use it to spin up a fresh cluster on Googles Kubernetes Engine.
But this can be done on large, complex projects. We successfully implemented dynamic review environments at Bugaboo for their eCommerce CMS platform, which had a large number of external dependencies. But it did take some effort.
Why bother?
Maybe I’ve now convinced you that it is possible to do CD without CI. But “Why bother?” you may be asking. “What’s the value to shuffling things around, if we’re still manually validating everything?” Well, I’m glad I imagined you asking that!
One reason to make such a change, is that it makes automating the rest easier. You can think of this as a sort of dancing skeleton for a complete CI/CD pipeline. By putting the broad pieces in place, there’s less work to do later as you flesh out the automated testing process, and replace manual QA processes with automated ones.
And that reason is probably sufficient on its own, but I think there’s a much more important reason, which would stand on its own even if absolutely no other CI were implemented (although I strongly believe you should implement at least a minimal CI).
The U-shaped cell
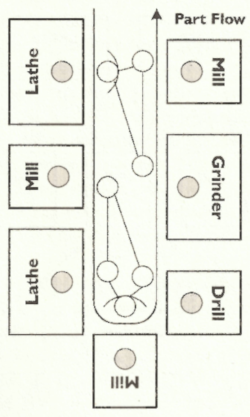
An interesting concept from Lean manufacturing is the U-shaped cell. Think of it like an assembly line bent in the middle, so that the input and output are next to each other.
Also, unlike a traditional assembly line, a single person works in a U-shaped cell. They do all the work from start to finish, that is needed in that cell. (There may be many U cells involved in the production of a single product, though.) Organized around the U are the various parts and tools needed to conduct their job. For a manufacturing plant, that may be a bucket of screws, a drill, a lathe, and some paint.
For our typical developer, we instead have tools like a text editor, version control, automated and manual tests, linters, etc.
Conventional workflows, like waterfall, and dare I say GitFlow, keep many of these tools separated by vast distances, with gatekeepers between them. The individual developer has control over only a small part of the process. This leads to a lot of wasted time, while stories wait for the next work center to pick them up. It leads to a lot of frustration, as developers get delayed feedback when something goes wrong. It leads to apathy, when developers assume that any problems will be caught later.
If we can put the individual developer at the center, and give them control over the entire process, these problems go away. And these problems go away even if we continue with manual, human validation!
In this scenario, the developer controls a feature from start to finish, only temporarily handing it off, say, to a QA engineer for validation, or to the end-user for acceptance testing. After each of these steps, the work goes right back to the developer, who then responds to the feedback, and when ready, advances to the next tool in the chain, until finally it is merged to master. In a sense, the human validation steps just become tools in the tool chain.
So while the absolute amount of work being done may not change, practically all queuing time is eliminated, the feedback cycle is shortened, and context is preserved in the mind of a single developer, rather than spread over multiple work centers. I see all of these as very worth-while goals.
A change of mindset
As with so many practices that may seem counter-intuitive, such as making money with free software, or improving efficiency by reducing batch size, what is necessary is a change of mindset.
The conventional mindset seeks to automate as much of the steps we’re currently doing, as a means toward the end of continuous delivery.
What I propose instead is to organize for continuous delivery, then optionally automate, where it makes sense.
Putting it into practice
Since originally writing this post back in 2019, I’ve developed a free 10-day email course, the Lean CD Bootcamp, which will walk you through a 10-step process to implement CD without automated CI on your own project. If this idea intrigues you, take the course (did I mention it’s free?). And if you still have questions or doubts, don’t hesitate to reach out to me.



{kind=link}