
Avoid merge conflicts, don't manage them
September 11, 2023
Or: why sweeping up the glass after an accident doesn't make you a responsible driverWhen discussing Continuous Integration on the interwebs, inevitably someone pops into the conversation with this hand grenade of wisdom:
BUT ACTUALLY… you don’t need Continuous Integration. It’s good enough to just merge mainline into your feature branch regularly. You get the same benefit, without the effort of changing your workflow.
Sounds nice. But it’s bullsh*t. And I’m going to prove it.
There must be a looser version of Godwin’s law that explains this phenomenon, with a dash of Dunbar’s number. Something like:
As the number of participants in a conversation grows, the probability of any particular fallacy being presented as truth, approaches 1.
But I digress. Let’s talk about feature branches and continuous integration.

First, let me set the backdrop for this discussion, with some general explanation and definitions.
Right off the bat, when I talk about Continuous Integration, I’m talking about “the activity of very frequently integrating work to the trunk of version control and verifying that the work is, to the best of our knowledge, releasable.” In particular, I’m not talking about the simple use of Jenkins or GitHub Actions or Circle-CI or any other tool that has CI in its name. CI is a practice, not a tool. The importance of this distinction will become apparent as we continue.
In contrast, most software development teams these days seem to use long-lived feature branches to develop software. Usually one branch per developer, working more or less in isolation, then after a few days, or sometimes even weeks, of work, they’ll do an integration ritual where they see what changes have occurred on the mainline branch while they were working, and go through the effort of integrating their code into mainline. A simplified diagram of this workflow looks something like this:

The practice of continuous integration all but eliminates this merge conflict problem. And now it should be obvious why using a tool called “CI” isn’t at all the same thing. (What’s more, this isn’t even the best thing about continuous integration, but that’s another topic.)
And this is where the BUT ACTUALLY folks will chime in. Here are some recent examples, taken from LinkedIn. (Slightly edited, and left anonymous to protect the guilty):
If work isn’t being merged “up” onto the main branch quickly enough then you need to merge “down” (i.e. bring the main branch into your working branch) regularly.
If you want to stay updated, take the pull from the main branch into your feature branch time to time.
This neglects to recognize that, no matter what, conflict resolution must occur at some point. If you don’t regularly rebase or merge your feature branch, and you don’t merge it until it’s “done,” then you will need to handle a lot of conflict resolution at the end.
Now before I tear apart the approach that these three folks have recommended, let me make it clear exactly what they are recommending.
If we imagine a feature that takes three weeks to complete, rather than waiting three weeks to see what has changed in mainline, we can periodically (perhaps daily?) merge (or rebase) mainline back into our feature branch.

Now this approach is not entirely without merit. There is often a benefit in tracking a changing mainline in your local branch. It’s usually easier to incrementally update your code to track one day’s worth of mainline changes at a time, than three weeks all at once. Although even this small benefit is made completely obsolete by continuous integration, as we’ll see in just a moment.
What matters for this discussion is that this workflow does absolutely nothing to eliminate code conflicts. Not even a little bit. In fact, it often increases the number of conflict resolutions you have to do. Any time a line or section of code has multiple changes applied in sequence, you’ll find yourself resolving conflicts every time you update mainline, rather than only once at the end.
“Okay, so there are the same number of conflicts. At least you’re resolving your own conflicts, like a responsible programmer citizen.”
This is just laughably naïve.
Where do you think those conflicts you just resolved came from? A conflict is like a two-sided coin. Every conflict is the result of two developers working on the same code in the same time window. Simply re-ordering it, or adding rules about “conflict etiquette” doesn’t resolve the problem. The only way to reduce conflicts is to reduce this time window. But now I’m jumping ahead.
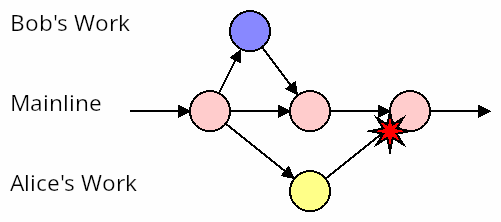
Consider two active branches: Bob’s branch and Alice’s branch. Bob and Alice are both waiting until their 3-week feature is done before merging. Unbeknownst to each of them, they’ve introduced a couple of conflicts, represented by the dashed red line. Then Bob merges his work, and it all integrates cleanly. Well done Bob!
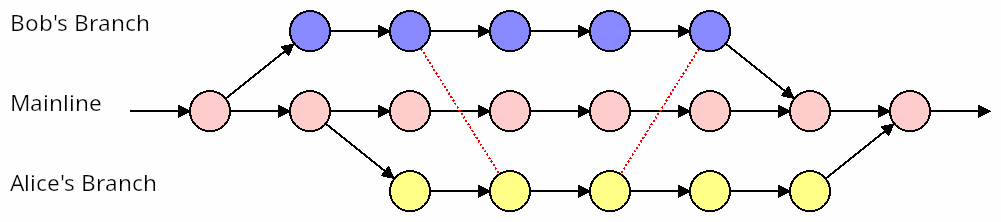
But then the next day Alice tries to merge, and discovers two conflicts that need to be resolved.
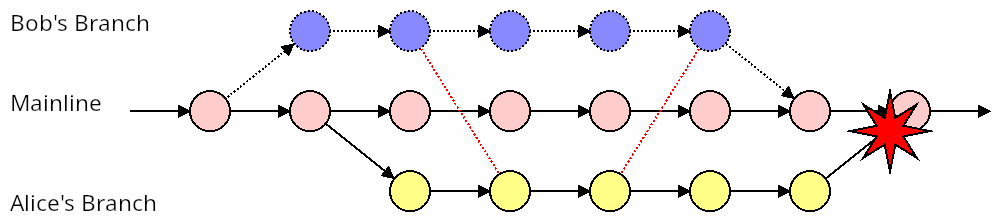
So let’s apply our “merge mainline into the branch frequently” strategy, and see how well it solves this particular problem.
In this scenario, both Bob and Alice are updating their branch with any changes found in mainline. But their own work remains isolated in their respective branches.
As a result, they’re both trodding along for weeks with no problems. Then Bob merges his change, without any fuss. Then Alice comes along and BANG!! She has a massive conflict, caused by Bob’s recently merged changes.
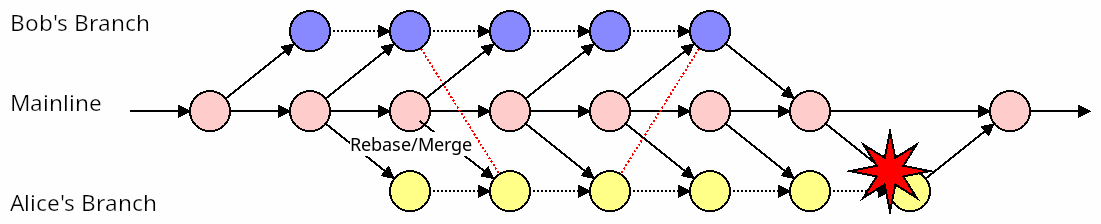
Nothing actually changed. Whatever the benefit of merging mainline into your branch frequently has for your own sanity, it makes no difference for your teammates in terms of conflict management. None. Zero. Zilch.
Here’s another quote from LinkedIn:
When making a change, it is the responsibility of the person making the more recent change to reconcile their local state with the shared state—the following person who changes the same code after you must do the same, etc.
This is like saying “When you’re in a car accident, make sure you’re not at fault. And clean up your half of the broken glass.”
What the actual f@#$?!?

Instead, let’s try to avoid collisions entirely!
Let’s now imagine that Bob and Alice are practicing continuous integration.
Specifically, this means that they’re integrating their work as frequently as possible. Many times per day, most likely. Every time they’ve added a bit of code that will eventually contribute to their goal, and the test suite passes, they make a commit, and merge it into mainline immediately.
Here’s what that looks like:
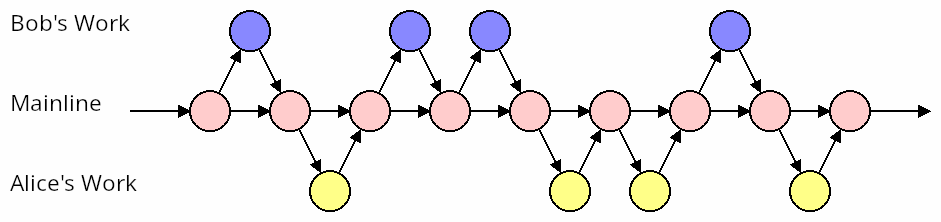
They’ve written the same functional changes. But with no conflicts. Magic!
How is that possible?
Well let’s remember what a conflict actually is. In another context that we should all be familiar with, we would call this a race condition. And we have various techniques for avoiding race conditions in our code. Can we apply those to our… eh.. Code?
Yes, Yes, we can.
One approach is to lock our changes. This is the approach taken by some ancient version control systems like CVS. In CVS, when you did a “checkout”, you were asking for a lock on files you wanted to change. This prevented anyone else from working on the same files. Conflicts avoided!
Of course, we know that when writing code, locks are slow and expensive, and introduce contention. So best to be avoided.
The other applicable approach for race avoidance (although there are others I won’t discuss here) is the use of atomic operations.
If your database, or CPU, or whatever underlying system, supports it, making an operation atomic avoids the possibility of a race condition.
Can we make our code changes atomic?
For all practical purposes, we can get extremely close (more on the exceptions in a moment).
Continuous Integration is as close as we can realistically get to atomic commits, and on human time scales, it’s usually as good.
When Bob is ready to make a small change, he makes sure he has an up-to-date version of mainline on his machine. He then makes his small change, and merges it into mainline. Within a few minutes. Or maybe an hour or two at most.
Then Alice comes along to add a small change that in our earlier, alternate, reality, would have conflicted with Bob’s change. But now Bob’s change is already in mainline. So Alice makes her change, integrating it into Bob’s change, without realizing there ever even was the possibility for a conflict. A few minutes later, she merges it.
Neither Bob nor Alice realize they’ve just averted disaster. There is no glass to clean up.
“That’s nice” some of you are saying. “But conflicts are still unavoidable. Someone is going to try update the same file as someone else. Eventually.”
Yes. Of course this is technically true.
But only technically.
Here’s the thing:
Such collisions are exceedingly rare. If you’re working in short iterations, on small bits of code, the chances of two random developers making a change to the same code at the same time is infinitesimal.
But this isn’t random. So the odds are even smaller. This is why you don’t already have more conflicts than you do. Usually, developers, or teams, divvy up their work in logical ways. Bob may be working on the database access layer, while Alice is working on the logging infrastructure. Only where these two subsystems intersect is a conflict even possible.
By way of anecdotal evidence, I once spent a year working on a monorepo with over 1,000 other developers, where we practiced continuous integration without feature branches. Not once in that year did I ever experience a code conflict. I’m sure they did happen. Occasionally. But it’s the exception. Not the rule. It’s absolutely not a problem worth optimizing for.
And now here’s the real magic: Even when these conflicts do occur, nobody really cares. They’re super trivial and easy to resolve. And even if they weren’t, by definition, they represent, at most, a few minutes, or maybe hours of work. If you had to throw it all away and start from scratch, the one time per year this occurred, it wouldn’t really matter much.

Let’s say you’re convinced that continuously integrating your work into mainline is the best way to avoid merge conflicts. What’s next?
The hardest part of continuous integration is not the technical aspects, but rather the human aspect. Humans are habitual creatures, and often resist suggestions to change the way they work, even if the way they work leads to a lot of car accidents merge conflicts.
This article is already long enough, so let me offer two resources in closing, if you find yourself needing additional help in this area.
First, MinimumCD.org is a great web site that explains in simple terms the minimum requirements to achieve Continuous Integration and the related practice of Continuous Delivery. The Starting the Journey page is a great place to start.
Second, I invite you to sign up for my daily email, The Daily Commit where I write about topics related to continuous integration, continuous delivery, and improving your software delivery process. Yes, it is daily. And yes, people stay subscribed. I promise you won’t regret it. And if you do, the unsubscribe link is at the bottom of every email. No hard feelings.


